Οπτικοποίηση δεδομένων
Μέχρι στιγμής μαθαίνουμε τη γλώσσα Python και πώς να χρησιμοποιούμε την Python, το δίκτυο και τις βάσεις δεδομένων, για να χειριζόμαστε δεδομένα.
Σε αυτό το κεφάλαιο, ρίχνουμε μια ματιά σε τρεις ολοκληρωμένες εφαρμογές που συγκεντρώνουν όλα όσα μάθαμε, για τη διαχείριση και την οπτικοποίηση δεδομένων. Μπορείτε να χρησιμοποιήσετε αυτές τις εφαρμογές ως δείγμα κώδικα για να ξεκινήσετε την επίλυση ενός πραγματικού προβλήματος.
Κάθε μία από τις εφαρμογές είναι ένα αρχείο ZIP, που μπορείτε να κατεβάσετε και να εξαγάγετε στον υπολογιστή σας καθώς και να το εκτελέσετε.
Δημιουργία ενός OpenStreetMap από γεωκωδικοποιημένα δεδομένα
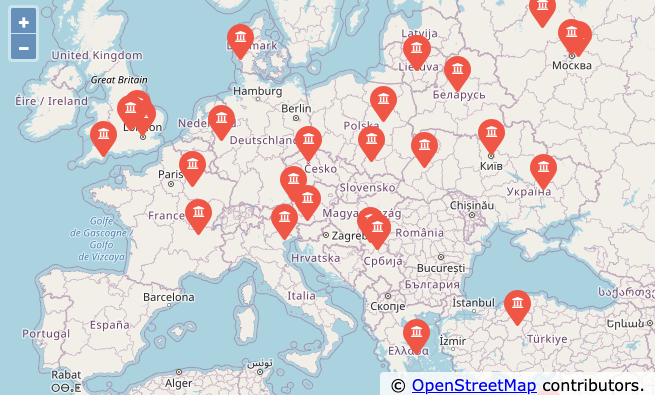
Σε αυτό το πρότζεκτ, χρησιμοποιούμε το API γεωκωδικοποίησης OpenStreetMap για να καθαρίσουμε ορισμένες γεωγραφικές τοποθεσίες, που έχουν εισαχθεί από τους χρήστες με ονόματα πανεπιστημίων και, στη συνέχεια, να τοποθετήσουμε τα δεδομένα σε ένα πραγματικό OpenStreetMap.
Για να ξεκινήσετε, κατεβάστε την εφαρμογή από:
www.gr.py4e.com/code3/opengeo.zip
Το πρώτο πρόβλημα που πρέπει να λύσουμε είναι ότι αυτά τα API γεωκωδικοποίησης είναι περιορισμένου ρυθμού, με έναν ορισμένο αριθμό αιτημάτων ανά ημέρα. Εάν έχετε πολλά δεδομένα, ίσως χρειαστεί να διακόψετε και να επανεκκινήσετε τη διαδικασία αναζήτησης αρκετές φορές. Έτσι χωρίζουμε το πρόβλημα σε δύο φάσεις.
Σε πρώτη φάση παίρνουμε τα δεδομένα εισόδου τη “έρευνάς” μας από το αρχείο where.data, τα διαβάζουμε μία γραμμή τη φορά, ανακτούμε τις γεωκωδικοποιημένες πληροφορίες από την Google και τις αποθηκεύουμε σε μια βάση δεδομένων, τη geodata.sqlite. Προτού χρησιμοποιήσουμε το API γεωκωδικοποίησης, για κάθε τοποθεσία που έχει εισαγάγει ο χρήστης, απλώς ελέγχουμε να δούμε αν έχουμε ήδη αποθηκεύσει τα δεδομένα για τη συγκεκριμένη γραμμή εισαγωγής. Η βάση δεδομένων λειτουργεί ως τοπική “κρυφή μνήμη” των δεδομένων γεωκωδικοποίησής μας, για να διασφαλίσουμε ότι δεν θα ζητήσουμε ποτέ από την Google τα ίδια δεδομένα δύο φορές.
Μπορείτε να επανεκκινήσετε τη διαδικασία ανά πάσα στιγμή, αφαιρώντας το αρχείο geodata.sqlite.
Εκτελέστε το πρόγραμμα geoload.py. Αυτό το πρόγραμμα θα διαβάσει τις γραμμές εισόδου στο where.data και για κάθε γραμμή θα ελέγξει αν βρίσκεται ήδη στη βάση δεδομένων. Εάν δεν έχουμε τα δεδομένα για την συγκεκριμένη τοποθεσία, θα καλέσει το API γεωκωδικοποίησης για να ανακτήσει τα δεδομένα και να τα αποθηκεύσει στη βάση δεδομένων.
Ακολουθεί ένα δείγμα εκτέλεσης, ενώ έχουν ήδη εισαχθει κάποια δεδομένα στη βάση δεδομένων:
Βρέθηκε στη βάση δεδομένων AGH University of Science and Technology
Βρέθηκε στη βάση δεδομένων Academy of Fine Arts Warsaw Poland
Βρέθηκε στη βάση δεδομένων American University in Cairo
Βρέθηκε στη βάση δεδομένων Arizona State University
Βρέθηκε στη βάση δεδομένων Athens Information Technology
Ανάκτηση της https://py4e-data.dr-chuck.net/
opengeo?q=BITS+Pilani
Ανακτήθηκαν 794 χαρακτήρες {"type":"FeatureColl
Ανάκτηση της https://py4e-data.dr-chuck.net/
opengeo?q=Babcock+University
Ανακτήθηκαν 760 χαρακτήρες {"type":"FeatureColl
Ανάκτηση της https://py4e-data.dr-chuck.net/
opengeo?q=Banaras+Hindu+University
Ανακτήθηκαν 866 χαρακτήρες {"type":"FeatureColl
...Οι πρώτες πέντε τοποθεσίες βρίσκονται ήδη στη βάση δεδομένων και έτσι παραλείπονται. Το πρόγραμμα σαρώνει μέχρι το σημείο όπου βρίσκει νέες τοποθεσίες και ξεκινά την ανάκτησή τους.
Το πρόγραμμα geoload.py μπορεί να διακοπεί ανά πάσα στιγμή και υπάρχει ένας μετρητής που μπορείτε να χρησιμοποιήσετε για να περιορίσετε τον αριθμό των κλήσεων στο API γεωκωδικοποίησης για κάθε εκτέλεση. Δεδομένου ότι το where.data έχει μόνο μερικές εκατοντάδες στοιχεία δεδομένων, δεν θα πρέπει να φτάσετε το ημερήσιο όριο ρυθμού, αλλά εάν είχατε περισσότερα δεδομένα, ενδέχεται να χρειαστούν αρκετές εκτελέσεις, σε αρκετές ημέρες, για να φτάσει η βάση δεδομένων σας να έχει όλα τα γεωκωδικοποιημένα δεδομένα για τα δεδομένα εισαγωγής σας.
Αφού φορτώσετε ορισμένα δεδομένα στο geodata.sqlite, μπορείτε να οπτικοποιήσετε τα δεδομένα χρησιμοποιώντας το πρόγραμμα geodump.py. Αυτό το πρόγραμμα διαβάζει τη βάση δεδομένων και δημιουργεί το αρχείο where.js με τη θέση, το γεωγραφικό πλάτος και μήκος, με τη μορφή εκτελέσιμου κώδικα JavaScript.
Μια εκτέλεση του προγράμματος geodump.py είναι η εξής:
AGH University of Science and Technology, Czarnowiejska,
Czarna Wieś, Krowodrza, Kraków, Lesser Poland
Voivodeship, 31-126, Poland 50.0657 19.91895
Academy of Fine Arts, Krakowskie Przedmieście,
Northern Śródmieście, Śródmieście, Warsaw, Masovian
Voivodeship, 00-046, Poland 52.239 21.0155
...
Υπήρχαν 260 εγραφές στο where.js
Ανοίξτε το where.html για να προβάλετε τα δεδομένα σε ένα πρόγραμμα περιήγησηςΤο αρχείο where.html αποτελείται από HTML και JavaScript, για την οπτικοποίηση ενός χάρτη Google. Διαβάζει τα πιο πρόσφατα δεδομένα στο where.js για να οπτικοποιήσει τα δεδομένα. Ακολουθεί η μορφή του αρχείου where.js:
myData = [
[50.0657,19.91895,
'AGH University of Science and Technology, Czarnowiejska,
Czarna Wieś, Krowodrza, Kraków, Lesser Poland
Voivodeship, 31-126, Poland '],
[52.239,21.0155,
'Academy of Fine Arts, Krakowskie Przedmieściee,
Śródmieście Północne, Śródmieście, Warsaw,
Masovian Voivodeship, 00-046, Poland'],
...
];Αυτή είναι μια μεταβλητή JavaScript που περιέχει μια λίστα λιστών. Η σύνταξη για τις σταθερές λίστας JavaScript είναι πολύ παρόμοια με την Python, επομένως η σύνταξη θα πρέπει να σας είναι οικεία.
Απλώς ανοίξτε το where.html, σε ένα πρόγραμμα περιήγησης, για να δείτε τις τοποθεσίες. Μπορείτε να τοποθετήσετε τον δείκτη του ποντικιού πάνω από κάθε καρφίτσα του χάρτη, για να βρείτε την τοποθεσία που επέστρεψε το API γεωκωδικοποίησης για την είσοδο που εισήγαγε ο χρήστης. Εάν δεν μπορείτε να δείτε τα δεδομένα όταν ανοίγετε το αρχείο where.html, ίσως χρειαστεί να ελέγξετε το JavaScript ή την κονσόλα προγραμματιστή, για το πρόγραμμα περιήγησής σας.
Οπτικοποίηση δικτύων και διασυνδέσεων
Σε αυτήν την εφαρμογή, θα εκτελέσουμε ορισμένες από τις λειτουργίες μιας μηχανής αναζήτησης. Αρχικά θα δημιουργήσουμε ένα μικρό υποσύνολο του ιστού και θα εκτελέσουμε μια απλοποιημένη έκδοση του αλγόριθμου κατάταξης σελίδων της Google, για να προσδιορίσουμε ποιες σελίδες είναι πιο συνδεδεμένες και, στη συνέχεια, θα οπτικοποιήσουμε την κατάταξη σελίδας και τη συνδεσιμότητα της μικρής μας γωνιάς του ιστού. Θα χρησιμοποιήσουμε τη βιβλιοθήκη οπτικοποίησης JavaScript D3 http://d3js.org/, για να παράγουμε την έξοδο οπτικοποίησης.
Μπορείτε να κατεβάσετε και να εξαγάγετε αυτήν την εφαρμογή από:
www.gr.py4e.com/code3/pagerank.zip
Το πρώτο πρόγραμμα προγράμματος (spider.py) ανιχνεύει έναν ιστότοπο και καταχωρεί μια σειρά σελίδων στη βάση δεδομένων (spider.sqlite), καταγράφοντας τους συνδέσμους μεταξύ των σελίδων. Μπορείτε να επανεκκινήσετε τη διαδικασία ανά πάσα στιγμή, αφαιρώντας το αρχείο spider.sqlite και εκτελώντας ξανά το spider.py.
Εισαγάγετε τη διεύθυνση url ιστού ή enter: http://www.dr-chuck.com/
['http://www.dr-chuck.com']
Πόσες σελίδες:2
1 http://www.dr-chuck.com/ 12
2 http://www.dr-chuck.com/csev-blog/ 57
Πόσες σελίδες:Σε αυτό το δείγμα εκτέλεσης, ζητήσαμε να ανιχνεύσει έναν ιστότοπο και να ανακτήσει δύο σελίδες. Εάν κάνετε επανεκκίνηση του προγράμματος και του πείτε να ανιχνεύσει περισσότερες σελίδες, δεν θα ανιχνεύσει ξανά καμία σελίδα που υπάρχει ήδη στη βάση δεδομένων. Με την επανεκκίνηση πηγαίνει σε μια τυχαία σελίδα που δεν ανιχνεύθηκε και ξεκινά από εκεί. Έτσι, κάθε διαδοχική εκτέλεση του spider.py λειτουργεί προσθετικά.
Εισαγάγετε τη διεύθυνση url ιστού ή enter: http://www.dr-chuck.com/
['http://www.dr-chuck.com']
Πόσες σελίδες:3
3 http://www.dr-chuck.com/csev-blog 57
4 http://www.dr-chuck.com/dr-chuck/resume/speaking.htm 1
5 http://www.dr-chuck.com/dr-chuck/resume/index.htm 13
Πόσες σελίδες:Μπορείτε να έχετε πολλαπλά σημεία εκκίνησης στην ίδια βάση δεδομένων — εντός του προγράμματος, αυτά ονομάζονται “ιστοί”. Το spider επιλέγει τυχαία μεταξύ όλων των συνδέσμων που δεν έχουν επισκεφτεί, σε όλους τους ιστούς, για να καθορίσει την επόμενη σελίδα προς ανίχνευση.
Εάν θέλετε να καταργήσετε τα περιεχόμενα του αρχείου spider.sqlite, μπορείτε να εκτελέσετε το spdump.py ως εξής:
(5, None, 1.0, 3, 'http://www.dr-chuck.com/csev-blog')
(3, None, 1.0, 4, 'http://www.dr-chuck.com/dr-chuck/resume/speaking.htm')
(1, None, 1.0, 2, 'http://www.dr-chuck.com/csev-blog/')
(1, None, 1.0, 5, 'http://www.dr-chuck.com/dr-chuck/resume/index.htm')
4 γραμμές.Αυτό δείχνει τον αριθμό των εισερχόμενων συνδέσμων, την παλιά κατάταξη της σελίδας, τη νέα κατάταξη της σελίδας, το αναγνωριστικό της σελίδας και τη διεύθυνση url της σελίδας. Το πρόγραμμα spdump.py εμφανίζει μόνο σελίδες που έχουν τουλάχιστον έναν εισερχόμενο σύνδεσμο προς αυτές.
Αφού έχετε μερικές σελίδες στη βάση δεδομένων, μπορείτε να εκτελέσετε το page rank στις σελίδες αυτές, χρησιμοποιώντας το πρόγραμμα sprank.py. Απλώς του λέτε πόσες επαναλήψεις κατάταξης σελίδων θα εκτελεστούν.
Πόσες επαναλήψεις:2
1 0.546848992536
2 0.226714939664
[(1, 0.559), (2, 0.659), (3, 0.985), (4, 2.135), (5, 0.659)]Μπορείτε να διαγράψετε ξανά τη βάση δεδομένων, για να δείτε ότι η κατάταξη σελίδας ενημερώνεται:
(5, 1.0, 0.985, 3, 'http://www.dr-chuck.com/csev-blog')
(3, 1.0, 2.135, 4, 'http://www.dr-chuck.com/dr-chuck/resume/speaking.htm')
(1, 1.0, 0.659, 2, 'http://www.dr-chuck.com/csev-blog/')
(1, 1.0, 0.659, 5, 'http://www.dr-chuck.com/dr-chuck/resume/index.htm')
4 γραμμές.Μπορείτε να εκτελέσετε το sprank.py όσες φορές θέλετε και απλά αυτό θα, βελτιώνει την κατάταξη της σελίδας κάθε φορά που το εκτελείτε. Μπορείτε ακόμη και να εκτελέσετε το sprank.py μερικές φορές και, στη συνέχεια, να κάνετε spider μερικές ακόμα σελίδες με το spider.py και, στη συνέχεια, να εκτελέσετε το sprank.py για να επανασυγκλίνετε οι τιμές κατάταξης σελίδας. Μια μηχανή αναζήτησης συνήθως εκτελεί και τα προγράμματα ανίχνευσης και κατάταξης συνεχώς.
Εάν θέλετε να επανεκκινήσετε τους υπολογισμούς κατάταξης σελίδας χωρίς να επαναφέρετε τις ιστοσελίδες, μπορείτε να χρησιμοποιήσετε το spreset.py και, στη συνέχεια, να επανεκκινήσετε το sprank.py.
Πόσες επαναλήψεις:50
1 0.546848992536
2 0.226714939664
3 0.0659516187242
4 0.0244199333
5 0.0102096489546
6 0.00610244329379
...
42 0.000109076928206
43 9.91987599002e-05
44 9.02151706798e-05
45 8.20451504471e-05
46 7.46150183837e-05
47 6.7857770908e-05
48 6.17124694224e-05
49 5.61236959327e-05
50 5.10410499467e-05
[(512, 0.0296), (1, 12.79), (2, 28.93), (3, 6.808), (4, 13.46)]Για κάθε επανάληψη του αλγορίθμου κατάταξης σελίδας εκτυπώνει τη μέση αλλαγή στην κατάταξη σελίδας ανά σελίδα. Το δίκτυο αρχικά είναι αρκετά ασταθές και έτσι οι μεμονωμένες τιμές κατάταξης σελίδας αλλάζουν δραματικά, μεταξύ των επαναλήψεων. Αλλά μετά από μερικές επαναλήψεις, η κατάταξη σελίδας συγκλίνει. Θα πρέπει να εκτελέσετε το sprank.py αρκετές φορές, ώστε οι τιμές της κατάταξης σελίδας να συγκλίνουν.
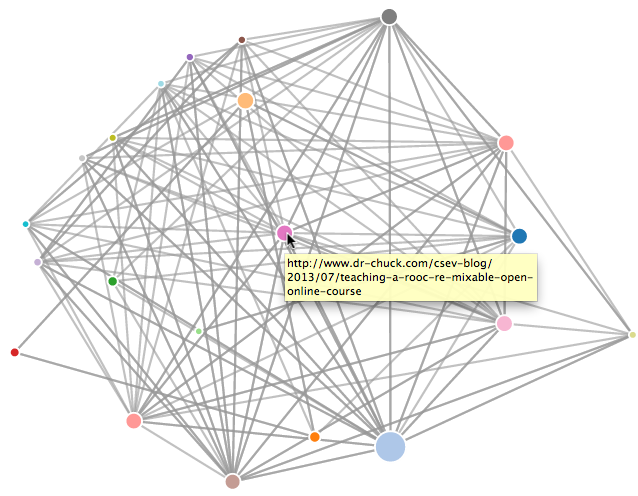
Εάν θέλετε να απεικονίσετε τις τρέχουσες κορυφαίες σελίδες, ως προς την κατάταξη σελίδων, εκτελέστε το spjson.py για να διαβάσει τη βάση δεδομένων και να εξάγει τα δεδομένα, για τις πιο συνδεδεμένες σελίδες, σε μορφή JSON για προβολή σε ένα πρόγραμμα περιήγησης ιστού.
Δημιουργία εξόδου JSON στο spider.js...
Πόσους κόμβους? 30
Ανοίξτε το force.html σε ένα πρόγραμμα περιήγησης για να προβάλετε την οπτικοποίησηΜπορείτε να δείτε αυτά τα δεδομένα ανοίγοντας το αρχείο force.html στο πρόγραμμα περιήγησής σας. Αυτό παρουσιάζει μια αυτόματη διάταξη των κόμβων και των συνδέσμων. Μπορείτε να κάνετε κλικ και να σύρετε οποιονδήποτε κόμβο και μπορείτε επίσης να κάνετε διπλό κλικ σε έναν κόμβο για να εντοπίσετε τη διεύθυνση URL που αντιπροσωπεύεται από τον κόμβο.
Εάν εκτελέσετε ξανά τα άλλα βοηθητικά προγράμματα, τότε εκτελέστε ξανά το spjson.py και πατήστε το refresh στο πρόγραμμα περιήγησης για να λάβετε τα νέα δεδομένα από το spider.json.
Οπτικοποίηση δεδομένων αλληλογραφίας
Μέχρι αυτό το σημείο του βιβλίου, έχετε εξοικειωθεί αρκετά με τα αρχεία δεδομένων mbox-short.txt και mbox.txt. Τώρα είναι καιρός να προχωρήσουμε την ανάλυσή μας για τα δεδομένα email στο επόμενο επίπεδο.
Στον πραγματικό κόσμο, μερικές φορές πρέπει να αφαιρέσετε κάποια δεδομένα αλληλογραφίας από διακομιστές. Αυτό μπορεί να πάρει αρκετό χρόνο και τα δεδομένα μπορεί να είναι ασυνεπή, γεμάτα σφάλματα και να χρειάζονται αρκετό καθάρισμα ή προσαρμογή. Σε αυτήν την ενότητα, εργαζόμαστε με μια εφαρμογή που είναι η πιο περίπλοκη μέχρι στιγμής, αφαιρούμε σχεδόν ένα gigabyte δεδομένων και τα οπτικοποιούμε.

Μπορείτε να κατεβάσετε αυτήν την εφαρμογή από:
https://www.gr.py4e.com/code3/gmane.zip
Θα χρησιμοποιήσουμε δεδομένα από μια δωρεάν υπηρεσία αρχειοθέτησης λιστών email, που ονομάζεται http://www.gmane.org. Αυτή η υπηρεσία είναι πολύ δημοφιλής σε έργα ανοιχτού κώδικα, επειδή παρέχει ένα ωραίο αρχείο με δυνατότητα αναζήτησης της δραστηριότητας ηλεκτρονικού ταχυδρομείου τους. Έχουν επίσης μια πολύ φιλελεύθερη πολιτική σχετικά με την πρόσβαση στα δεδομένα τους, μέσω του API τους. Δεν έχουν όρια τιμών, αλλά θα σας παρακαλούσα να μην υπερφορτώνετε την υπηρεσία τους και να λαμβάνετε μόνο τα δεδομένα που χρειάζεστε. Μπορείτε να διαβάσετε τους όρους και τις προϋποθέσεις του gmane σε αυτή τη σελίδα:
http://www.gmane.org/export.php
Είναι πολύ σημαντικό να χρησιμοποιείτε υπεύθυνα τα δεδομένα του gmane.org, προσθέτοντας καθυστερήσεις στην πρόσβασή σας στις υπηρεσίες του και κατανέμοντας μακροχρόνιες εργασίας σε μεγαλύτερα χρονικά διαστήματα. Μην καταχραστείτε αυτήν τη δωρεάν υπηρεσία και μην την καταστρέψετε, για εμάς τους υπόλοιπους.
Όταν τα δεδομένα email του Sakai κυκλοφόρησαν χρησιμοποιώντας αυτό το λογισμικό, παρήγαγε σχεδόν ένα Gigabyte δεδομένων και χρειάστηκαν μια σειρά εκτελέσεων, σε αρκετές ημέρες. Το αρχείο README.txt στο παραπάνω ZIP ενδέχεται να έχει οδηγίες σχετικά με το πώς μπορείτε να κάνετε λήψη ενός προκαθορισμένου αντιγράφου του αρχείου content.sqlite, για το μεγαλύτερο μέρος του σώματος ηλεκτρονικού ταχυδρομείου του Sakai, ώστε να μην χρειαστεί να κάνετε λήψη, επί πέντε ημέρες, μόνο για την εκτέλεση των προγραμμάτων. Εάν κάνετε λήψη του προκαταρκτικού περιεχομένου, θα πρέπει να εκτελέσετε τη διαδικασία spidering για να το ενημερώσετε με τα πιο πρόσφατα μηνύματα.
Το πρώτο βήμα είναι να κάνετε ανίχνευση του αποθετηρίου του gmane. Η βασική διεύθυνση URL είναι κωδικοποιημένη στο gmane.py και είναι κωδικοποιημένη στη Sakai developer list. Μπορείτε να δημιουργήσετε ένα άλλο αποθετήριο, αλλάζοντας αυτό το βασικό url. Φροντίστε να διαγράψετε το αρχείο content.sqlite εάν αλλάξετε τη βασική διεύθυνση url.
Το αρχείο gmane.py λειτουργεί ως υπεύθυνος ανιχνευτής ιστού, προσωρινής αποθήκευσης, καθώς εκτελείται αργά και ανακτά ένα μήνυμα αλληλογραφίας ανά δευτερόλεπτο, ώστε να αποφευχθεί η υπερφόρτωση του gmane. Αποθηκεύει όλα τα δεδομένα του σε μια βάση δεδομένων και μπορεί να διακόπτεται και να επανεκκινείται όσο συχνά χρειάζεται. Ενδέχεται να χρειαστούν πολλές ώρες για να ανακτηθούν όλα τα δεδομένα. Επομένως, ίσως χρειαστεί να κάνετε επανεκκίνηση αρκετές φορές.
Ακολουθεί μια εκτέλεση από gmane.py που ανακτά τα τελευταία πέντε μηνύματα της λίστας προγραμματιστών Sakai:
Πόσα μηνύματα:10
http://download.gmane.org/gmane.comp.cms.sakai.devel/51410/51411 9460
[email protected] 2013-04-05 re: [building ...
http://download.gmane.org/gmane.comp.cms.sakai.devel/51411/51412 3379
[email protected] 2013-04-06 re: [building ...
http://download.gmane.org/gmane.comp.cms.sakai.devel/51412/51413 9903
[email protected] 2013-04-05 [building sakai] melete 2.9 oracle ...
http://download.gmane.org/gmane.comp.cms.sakai.devel/51413/51414 349265
[email protected] 2013-04-07 [building sakai] ...
http://download.gmane.org/gmane.comp.cms.sakai.devel/51414/51415 3481
[email protected] 2013-04-07 re: ...
http://download.gmane.org/gmane.comp.cms.sakai.devel/51415/51416 0
Δεν ξεκινά με FromΤο πρόγραμμα σαρώνει το content.sqlite από το id 0 μέχρι τον πρώτο αριθμό μηνύματος που δεν έχει ήδη ελεγχθεί και αρχίζει να σαρώνει το μήνυμα αυτό. Συνεχίζει να εκτελείται, έως ότου συμπληρώσει τον επιθυμητό αριθμό μηνυμάτων ή μέχρι να φτάσει σε μια σελίδα που δεν φαίνεται να αποτελεί ένα σωστά διαμορφωμένο μήνυμα.
Μερικές φορές στο gmane.org μπορεί να λείπει κάποιο μήνυμα. Ίσως οι διαχειριστές να μπορούν να διαγράψουν μηνύματα ή ίσως να έχουν χαθεί. Εάν η ανίχνευσή σας σταματήσει και φαίνεται να συνάντησε κάποιο μήνυμα που λείπει, μεταβείτε στο SQLite Manager και προσθέστε μια εγγραφή με το αναγνωριστικό που λείπει, αφήνοντας όλα τα άλλα πεδία κενά και επανεκκινήστε το gmane.py. Αυτό θα ξεκολλήσει τη διαδικασία ανίχνευσης και θα της επιτρέψει να συνεχιστεί. Αυτά τα κενά μηνύματα θα αγνοηθούν στην επόμενη φάση της διαδικασίας.
Το καλό είναι ότι, αφού έχετε ανιχνεύσει όλα τα μηνύματα και τα έχετε στο content.sqlite, μπορείτε να εκτελέσετε ξανά το gmane.py για να λάβετε τα νέα μηνύματα που αποστέλλονται στη λίστα.
Τα δεδομένα content.sqlite είναι αρκετά ακατέργαστα, με ένα αναποτελεσματικό μοντέλο δεδομένων και δεν είναι συμπιεσμένα. Αυτό γίνεται σκόπιμα, καθώς σας επιτρέπει να κοιτάξετε το content.sqlite, στο SQLite Manager, για να εντοπίσετε προβλήματα με τη διαδικασία ανίχνευσης. Δεν θα ήταν καλή ιδέα το να εκτελέσετε οποιαδήποτε ερωτήματα σε αυτήν τη βάση δεδομένων, καθώς θα ήταν αρκετά αργό.
Η δεύτερη διαδικασία είναι η εκτέλεση του προγράμματος gmodel.py. Αυτό το πρόγραμμα διαβάζει τα ακατέργαστα δεδομένα από το content.sqlite και παράγει μια καθαρισμένη και καλά διαμορφωμένη έκδοση των δεδομένων στο αρχείο index.sqlite. Αυτό το αρχείο θα είναι πολύ μικρότερο (συχνά εώς και 10 φορές μικρότερο) από το content.sqlite, επειδή συμπιέζει την κεφαλίδα και το σώμα κειμένου.
Κάθε φορά που εκτελείται το gmodel.py αυτό διαγράφει και αναδημιουργεί το index.sqlite, επιτρέποντάς σας να προσαρμόσετε τις παραμέτρους του και να επεξεργαστείτε τους πίνακες αντιστοίχισης στο content.sqlite, για να τροποποιήσετε τη διαδικασία καθαρισμού δεδομένων. Αυτό είναι ένα δείγμα εκτέλεσης του gmodel.py. Εκτυπώνει μια γραμμή, κάθε φορά που υποβάλλονται σε επεξεργασία 250 μηνύματα αλληλογραφίας, ώστε να μπορείτε να δείτε κάποια πρόοδο που συμβαίνει, καθώς αυτό το πρόγραμμα μπορεί να εκτελείται για αρκετό χρονικό διάστημα, μιας και επεξεργάζεται σχεδόν ένα Gigabyte δεδομένων αλληλογραφίας.
Loaded allsenders 1588 and mapping 28 dns mapping 1
1 2005-12-08T23:34:30-06:00 [email protected]
251 2005-12-22T10:03:20-08:00 [email protected]
501 2006-01-12T11:17:34-05:00 [email protected]
751 2006-01-24T11:13:28-08:00 [email protected]
...Το πρόγραμμα gmodel.py χειρίζεται μια σειρά από εργασίες καθαρισμού δεδομένων.
Τα ονόματα τομέα διασπώνται σε δύο τμήματα αναζητώντας τα .com, .org, .edu και .net. Άλλα ονόματα τομέα διασπώνται σε τρία επίπεδα. Έτσι το si.umich.edu γίνεται umich.edu και το caret.cam.ac.uk γίνεται cam.ac.uk. Οι διευθύνσεις email επίσης εξαναγκάζονται σε πεζά γράμματα, και ορισμένες από τις διευθύνσεις @gmane.org, όπως η παρακάτω
[email protected]μετατρέπονται στην πραγματική διεύθυνση, όποτε υπάρχει μια αντίστοιχη πραγματική διεύθυνση ηλεκτρονικού ταχυδρομείου σε άλλο σημείο του σώματος του μηνύματος.
Στη βάση δεδομένων mapping.sqlite υπάρχουν δύο πίνακες που σας επιτρέπουν να αντιστοιχίσετε τόσο ονόματα τομέα όσο και μεμονωμένες διευθύνσεις email, που αλλάζουν κατά τη διάρκεια ζωής της λίστας email. Για παράδειγμα, ο Steve Githens χρησιμοποίησε τις ακόλουθες διευθύνσεις ηλεκτρονικού ταχυδρομείου, καθώς άλλαζε θέσεις εργασίας κατά τη διάρκεια ζωής της λίστας προγραμματιστών Sakai:
[email protected]
[email protected]
[email protected]Μπορούμε να προσθέσουμε δύο εγγραφές στον πίνακα Mapping στο mapping.sqlite, έτσι το gmodel.py θα αντιστοιχίσει και τις τρεις σε μία διεύθυνση:
[email protected] -> [email protected]
[email protected] -> [email protected]Μπορείτε επίσης να καταχωρήσετε παρόμοιες εγγραφές στον πίνακα DNSMapping, εάν υπάρχουν πολλά ονόματα DNS που θέλετε να αντιστοιχιστούν σε ένα μόνο DNS. Η ακόλουθη αντιστοίχιση προστέθηκε στα δεδομένα Sakai:
iupui.edu -> indiana.eduΈτσι, όλοι οι λογαριασμοί από τις διάφορες πανεπιστημιουπόλεις των Πανεπιστημίων της Ιντιάνα παρακολουθούνται μαζί.
Μπορείτε να εκτελέσετε ξανά το gmodel.py, ξανά και ξανά, καθώς εξετάζετε τα δεδομένα και να προσθέτετε αντιστοιχίσεις για να κάνετε τα δεδομένα καθαρότερα και καθαρότερα. Όταν τελειώσετε, θα έχετε μια ωραία ευρετηριασμένη έκδοση του ηλεκτρονικού ταχυδρομείου, στο index.sqlite. Αυτό είναι το αρχείο που χρησιμοποιείται για την ανάλυση δεδομένων. Με αυτό το αρχείο, η ανάλυση δεδομένων θα είναι πολύ γρήγορη.
Η πρώτη, απλούστερη ανάλυση δεδομένων είναι να προσδιοριστεί “ποιος έστειλε τα περισσότερα μηνύματα;” και “ποιος οργανισμός έστειλε τα περισσότερα mail”; Αυτό γίνεται χρησιμοποιώντας το gbasic.py:
Πόσες διαγραφές; 5
Φορτωμένα μηνύματα= 51330 θέματα= 25033 αποστολείς= 1584
Κορυφαίοι 5 συμμετέχοντες στη λίστα Email
[email protected] 2657
[email protected] 1742
[email protected] 1591
[email protected] 1304
[email protected] 1184
Κορυφαίοι 5 οργανισμοί στη λίστα Email
gmail.com 7339
umich.edu 6243
uct.ac.za 2451
indiana.edu 2258
unicon.net 2055Σημειώστε πόσο πιο γρήγορα εκτελείται το gbasic.py σε σύγκριση με το gmane.py ή ακόμα και το gmodel.py. Όλα λειτουργούν στα ίδια δεδομένα, αλλά το gbasic.py χρησιμοποιεί τα συμπιεσμένα και κανονικοποιημένα δεδομένα του index.sqlite. Εάν έχετε πολλά δεδομένα για διαχείριση, μια διαδικασία πολλαπλών βημάτων, όπως αυτή σε αυτήν την εφαρμογή, μπορεί να χρειαστεί λίγο περισσότερο χρόνο για να αναπτυχθεί, αλλά θα σας εξοικονομήσει πολύ χρόνο όταν αρχίσετε πραγματικά να εξερευνάτε και να οπτικοποιείτε τα δεδομένα σας.
Μπορείτε να δημιουργήσετε μια απλή απεικόνιση της συχνότητας λέξης, στις γραμμές θέματος του αρχείου gword.py:
Εύρος μετρήσεων: 33229 129
Έξοδος γραμμένη στο gword.jsΑυτό παράγει το αρχείο gword.js το οποίο μπορείτε να οπτικοποιήσετε, χρησιμοποιώντας gword.htm, για να δημιουργήσετε ένα σύννεφο λέξεων παρόμοιο με αυτό στην αρχή αυτής της ενότητας.
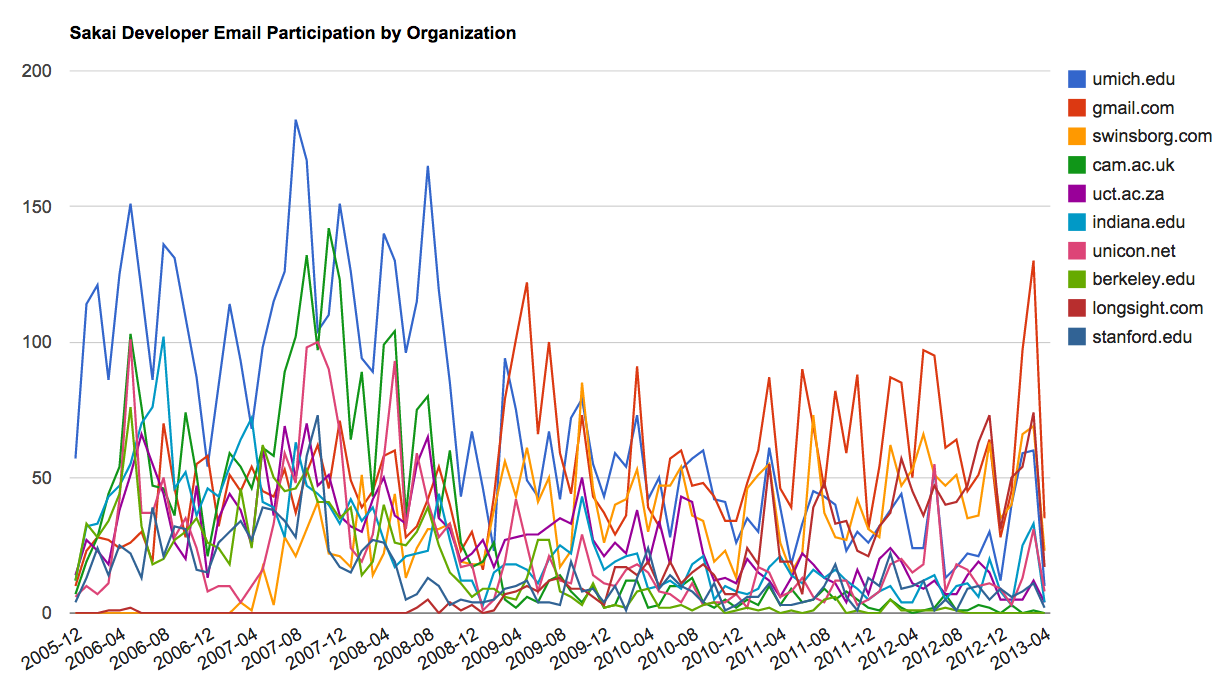
Μια δεύτερη οπτικοποίηση παράγεται από το gline.py. Υπολογίζει τη συμμετοχή μέσω email από οργανισμούς με την πάροδο του χρόνου.
Φορτωμένα μηνύματα= 51330 αποστολείς= 1584
Κορυφαίοι 10 Οργανισμοί
['gmail.com', 'umich.edu', 'uct.ac.za', 'indiana.edu',
'unicon.net', 'tfd.co.uk', 'berkeley.edu', 'longsight.com',
'stanford.edu', 'ox.ac.uk']
Output written to gline.jsΗ έξοδός του γράφεται στο gline.js το οποίο οπτικοποιείται χρησιμοποιώντας gline.htm.
Αυτή είναι μια σχετικά περίπλοκη και εξελιγμένη εφαρμογή που διαθέτει δυνατότητες για την ανάκτηση, τον καθαρισμό και την οπτικοποίηση πραγματικών δεδομένων.
Αν εντοπίσετε κάποιο λάθος σε αυτό το βιβλίο μην διστάσετε να μου στείλετε τη διόρθωση στο Github.